“Forget Killer Robots - Bias Is the Real AI Danger” - John Giannandrea, ehemals Leiter AI bei Google, 2017 MIT Technology Review.
Wenn Medien sich mit KI beschäftigen, dann sind es meist die ganz grossen Bilder und Geschichten. Roboter, die aus der Zukunft kommen und uns wahlweise auslöschen oder beschützen, künstliche Intelligenzen, die ein Gewissen entwickeln oder Artificial General Intelligence, die Fähigkeiten besitzt, jede intellektuelle Aufgabe zu verstehen und zu lösen, wie auch ein Mensch es kann. Womit sich viele Wissenschaftler und administratives und juristisches Fachpersonal im Rahmen der DGSVO - Regulierung zum Schutz persönlicher Daten - oder des EU Artificial Intelligence Act - Regulierung künstlicher Intelligenz in Geschäftsmodellen - auseinandersetzen, also der konkreten Arbeit an den Schwächen der schon eingesetzten Modelle der künstlichen Intelligenz, ist selten eine spannende Hintergrundstory oder ein grosser medialer Aufmacher. Dabei betreffen die Funktionsweisen und Schwächen produktiver Systeme das Leben der meisten Menschen im Hier und Jetzt. Soziale Netzwerke mit problematischen Funktionalitäten, Machine Learning im Rechts- und Polizeisystem, Entscheidungssituationen autonom fahrender Fahrzeuge oder die Bearbeitung von Hypotheken oder Kreditvergaben durch Banken und Versicherungen sind nur einige Beispiele aus dem täglichen Leben der meisten von uns.
Title Image by: Sigmund on Unsplash
Im oben verlinkten Beitrag aus der MIT Technology Review wird sehr konkret darauf hingewiesen, wo die Bedrohungen dieser Systeme momentan tatsächlich liegen - in Verzerrungen (gewollten oder ungewollten) der Trainingsdaten der Machine-Learning-Modelle. Als nötige Kernkompetenz für die Nutzung einfacher cloud-basierter KI-Systeme wird die Identifikation und Entfernung dieser Verzerrungen aus den Trainingsdaten beschrieben. Eine Kernkompetenz für Nicht-Spezialisten, die benutzerfreundliche Oberflächen eines Cloud Anbieters nutzen, wo doch schon ein gesellschaftlich breiteres Verständnis über datenbasierte Geschäftsmodelle und die grundlegende Funktionsweise statistischer Modelle kaum umzusetzen ist. Darüber hinaus lässt sich die Funktionsweise komplexer KI-Systeme nicht vollständig durchschauen - Deep Learning ist eine ‘Dark Black Box’ wie der Autor des Beitrages in einem weiteren Artikel ‘The Dark Secret At the Heart of AI’ ausführlich beschreibt. MIT Technology Review
Nicht ohne Grund folgen auf eine Phase der Appelle an die Selbstkontrolle der Anbieter von KI-Systemen und an Unternehmen, die datenbasierte Geschäftsmodelle verfolgen, jetzt Ansätze zu einer stärkeren rechtlichen Regulierung, ausgehend von der Europäischen Union. Nach einer Stärkung des Grundrechtes auf Schutz der personenbezogenen Daten durch die DGSVO im Jahr 2016 folgt seit 2021 die Arbeit am EU Artificial Intelligence Act, einem Vorschlag, wie KI-Anwendungen in Risikokategorien zu unterteilen sind, die dann unterschiedlich zu regulieren sind. Schon vor diesen Eingriffen grosser Regulierungsbehörden finden sich einige Unternehmen und Verwaltungen, die sich offen mit ethischen Fragestellungen in Bezug auf ihre Daten und KI-Systeme auseinandersetzen. Frameworks von algorithm watch, Studien in der Verwaltung oder eine Ethik Charta können helfen, das Thema strukturiert anzugehen. Über den Datenschutz hinausgehend bietet die Beschäftigung mit ethischen Fragestellungen in diesem Bereich die Möglichkeit, Reputationsschäden bei (unbeabsichtigtem) Fehlverhalten zu vermeiden, als auch Regulationen vorwegzunehmen und für rechtliche Rahmenbedingungen der Zukunft bereit zu sein.
 Photo by robin mikalsen on Unsplash
Photo by robin mikalsen on Unsplash
Werte ethischen Handelns und der Lebenszyklus von Daten
Exemplarisch für die unterschiedlichen oben aufgeführten Ansätze will ich die Swico Ethik Charta kurz einführen. Sie definiert 6 Werte ethischen Handelns, die es gilt zu verfolgen, wann immer es möglich ist: Schadenvermeidung, Gerechtigkeit, Autonomie, Kontrolle, Transparenz und Rechenschaft. Hinzukommen 4 Hauptschritte des Lebenszyklus von Daten, die für jeden Wertebereich getrennt zu beurteilen sind: Erzeugung und Aquirierung von Daten, Speicherung und Management von Daten, Datenanalyse und Wissensgenerierung sowie Produkte und Dienstleistungen. Eine Checkliste für den Abgleich des eigenen Unternehmens oder der eigenen Produkte mit der Ethik Charta hinsichtlich der praktischen Umsetzung und Umsetzbarkeit wurde eingeführt, an der über ausformulierte Aussagen geprüft werden kann, ob sich das jeweilige Produkt/Unternehmen in einem Widerspruch zu den Wertedimensionen befindet oder eine Orientierung an der Ethik Charta umsetzbar ist.
 Photo by
Photo by Data Science Ethical Matrix
Im Zuge der Beschäftigung mit Business-Cases, welche Modelle maschinellen Lernens enthalten könnten, ist es wichtig, ethische Fragestellungen von Anfang mit zu berücksichtigen. Die Gestaltung der Algorithmen und Trainingsdaten bleibt in grossen Teilen die Verantwortung der Data Scientists und Machine Learning Engineers, allerdings ist es vor allem die Businessseite, die den zu modellierenden Prozess, alle am Prozess beteiligten Gruppen von stakeholdern und historische Besonderheiten am Besten kennt. Wie unten gezeigt, ist die Integration aller vom Algorithmus und der automatisierten Entscheidungsfindung betroffenen Gruppen im Designprozess der Schlüssel, um Benachteiligungen aus automatisierten Entscheidungssystemen früh zu erkennen und umfassend zu diskutieren.
Ein Beispiel zeigt deutlich eine mögliche Diskussion über die Optimierung eines Maschine Learning Algorithmus. Aus Sicht der Auftraggeber sind vielleicht möglichst viele automatische Entscheidungen gewünscht, um Personalkosten zu sparen. Aus Sicht des Entwicklers liegt die Entscheidungsschwelle des Modells aus Gründen der Modellgüte aber niedriger und weniger automatische Entscheidungen wären die Folge. Dieser Zielkonflikt lässt sich mit einer finanziellen Kosten-Nutzen-Matrix auflösen, die falsch-negativen und falsch-positiven Vorhersagen klare monetäre Kosten gegenüberstellt. Ähnlich verhält es sich mit ethischen Fragestellungen, auch hier entstehen (monetäre, moralische, gesellschaftliche) Kosten falscher Entscheidungen, die es zu bewerten und zu diskutieren gilt.
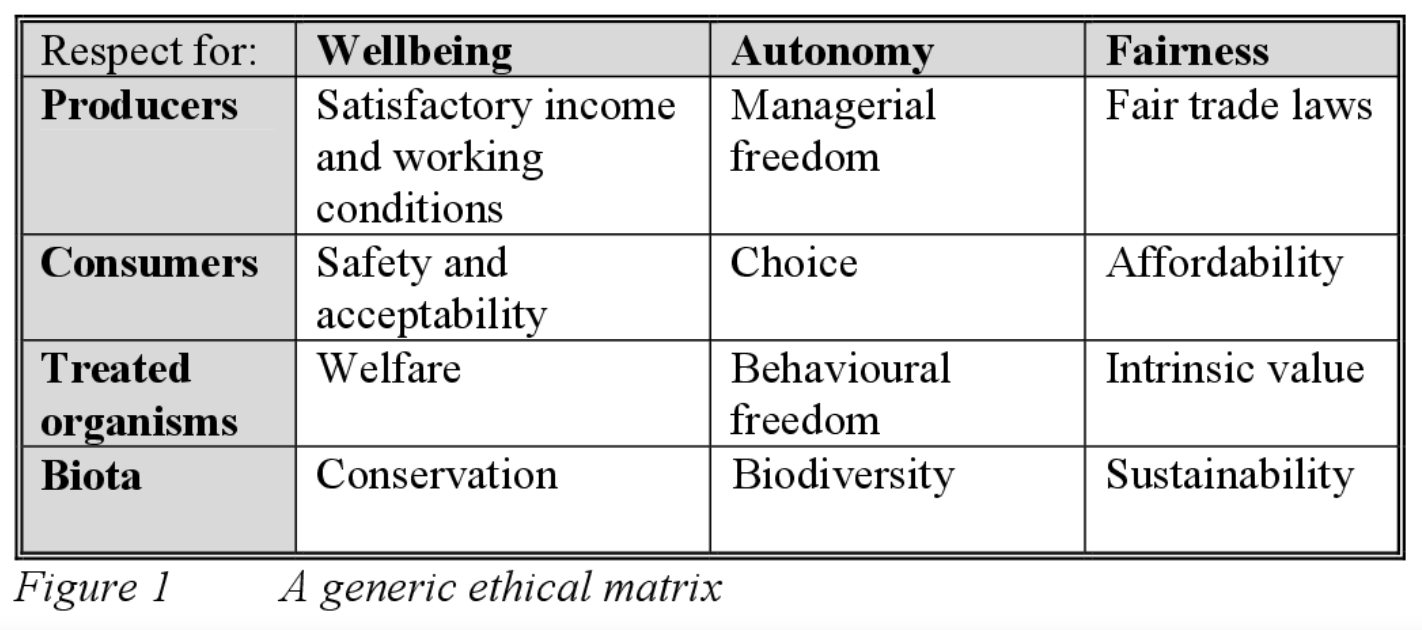 Abbildung: O’Neill und Gunn
Abbildung: O’Neill und Gunn
Die Beschäftigung mit (ungewollten) Benachteiligungen hilft diese Benachteiligungen zu verbessern oder zumindest die Beschäftigung damit transparent zu dokumentieren. O’Neill und Gunn schlagen hier eine Matrix vor, die alle Rollen von Beteiligten und Betroffenen integriert und gegenläufige Ziele einander gegenüberstellt. Dieses Ethik-Auditing entsteht vor dem Hintergrund zu erkennen und zu bewerten, wie Ungleichbehandlung in KI-Systeme eingebettet ist und von ihnen verstärkt wird. Die Entwickler dieser Systeme tragen demnach eine besondere Art von Verantwortung für die moralischen Konsequenzen der von Ihnen erstellten Modelle.
Im Designprozess der Modelle werden jetzt zusätzliche Verantwortlicheiten wahrgenommen, indem Entscheidungen transparent gemacht werden. Die erstellte Matrix gibt keine Hinweise darauf wie der Algortihmus zu entwickeln oder zu implementieren ist, sie trägt aber dem ernsthaften Bedürfnis nach ethischer Reflektion Rechnung. Ein praktisches Beispiel: Die Modellentwickler streben vielleicht ein möglichst passendes Modell an, welches allerdings bestimmte Gruppen von Kunden benachteiligt. Aus Sicht des Entwicklers nicht unbedingt ein Problem, da die Trainingsdaten diese Benachteiligung bereits historisch enthalten. Aus Sicht der Betroffenen stellte diese Benachteiligung schon vor der automatisierten Entscheidung ein Problem dar - jetzt bietet sich die Möglichkeit das zu thematisieren und im Idealfall aufzulösen.
Wie oben beschrieben kann die Bearbeitung der Matrix mit echten Vertretern aller stakeholder-Gruppen erfolgen oder im Prozess der Diskussion nehmen die Beteiligten jeweils unterschiedliche Rollen ein und stellen ihre Ziele gegenüber. Dabei werden drei ethische Prinzipien thematisiert: Wohlbefinden, Autonomie und Gerechtigkeit. Die stakeholder-Gruppen überlegen, inwiefern sie auf den drei Dimensionen durch Einführung der neuen Technologie betroffen wären. Die Matrix ermöglicht, ohne technisches Verständnis oder Expertise auf dem Feld der Ethik am Designprozess teilzuhaben.
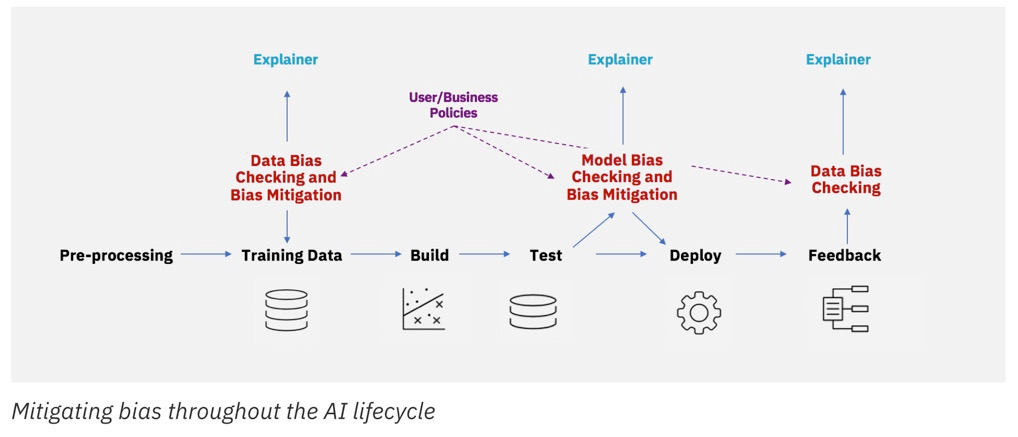 Abbildung: AIF 360
Abbildung: AIF 360
Bias Detection
Wie oben beschrieben liegen viele der Probleme von Benachteiligung durch Algorithmen in verzerrten Trainingsdaten begründet. Daten, die über Jahre gesammelt oder erzeugt wurden und die jenen Bias, der zu individuellen Benachteiligungen oder der Benachteiligung von ganzen Gruppen führt, schon enthalten. Mit verschiedenen Toolkits und Algorithmen lässt sich ein vorhandener Datensatz auf Bias testen. Vorausgehend muss natürlich bestimmt werden, welche Vorteile oder Benachteiligungen bei bestimmten Gruppen in den Daten erwartbar sind - womit wir wieder bei der Verantwortung der Businessseite sind. Dahinter stehen Konzepte von Fairness, welche sich auf Individuen und Gruppen anwenden lassen.
Mit Toolkits wie AIF 360 lassen sich Metriken berechnen, die beispielsweise prüfen, wie viel wahrscheinlicher es ist, dass der jeweilige Algorithmus bei jungen Männer eine positive Prediction ausgibt. Nach der Idenfikation besteht die Möglichkeit mit verschiedenen Techniken einen Mitigation des Bias voranzutreiben. Weitere Möglichkeiten finden sich beispielsweise bei FairML.
Zusammenfassung
Mit diesen Überlegungen ist gerade einmal die Oberfläche dieses sehr umfangreichen und wichtigen Teiles der wissenschaftlichen Debatte zum Thema Ethik im Bereich Machine Learning berührt. Neben neuen technischen Möglichkeiten, einer immer tiefer gehenden Erforschung aber auch durch institutionellen und staatlichen Druck zur Befolgung ethischer Vorgaben, wird sich das Thema mit zunehmender Geschwindigkeit entwickeln. Wichtige ethische Debatten wurden angestossen und aus rechtlicher Perspektive kommen mit dem Einsatz von KI grosse Herausforderungen auf Staat und Gesellschaft zu.
Thank you, and have a beautiful day!